Fine-Tune FLAN-T5 Model with RL(PPO)
Fine-tune a FLAN-T5 model to generate less toxic content with Meta AI's hate speech reward model. Proximal Policy Optimization (PPO) is used to fine-tune and reduce the model's toxicity.
Introduction
What is a FLAN-T5?
FLAN-T5 is a very good general purpose Large Language Model that is capable of doing a whole lot of things. It is an enhance version of T5 that has been finetuned in a mixture of tasks.
What is LLM Fine-Tuning and Reinforcement Learning?
Fine tuning is a supervised learning process where you use a data set of labelled examples to update the weights of the Large Language Model. The labelled examples are prompt completion pairs, the fine-tuning process extends the trainging of the model to improve its ability to generate good completions for a specific task.
Reinforcement Learning is a type of machine learning in which an agent learns to make decisions related to a specific goal by taking actions in an environment, with the objective of maximizing some notion of a cumulative reward. In this framework, the agent continuously learns from its experiences by taking actions, observing the resulting changes in the environment, and receiving rewards or penalties, based on the outcomes of its actions.
What is RLHF (Reinforcement Learning with Human Feedback)?
A technique to finetune large language models with human feedback is called Reinforcement Learning with Human Feedback. As the name suggests, RLHF uses reinforcement learning, or RL for short, to finetune the LLM with human feedback data, resulting in a model that is better aligned with human preferences.
RLHF can be used to make sure that your model produces outputs that maximize usefulness and relevance to the input prompt. RLHF can help minimize the potential for harm. Model can be trained to give caveats that acknowledge their limitations and to avoid toxic language and topics.
One potentially exciting application of RLHF is the personalizations of LLM’s, where models learn the preferences of each individual user through a continuous feedback process.
The first step in fine-tuning an LLM with RLHF is to select a model to work with and use it to prepare a data set for human feedback. The model you choose should have some capability to carry out the task you are interested in, whether this is text summarization, question answering or something else.
You’ll then use this LLM along with a prompt data set to generate a number of different responses for each prompt. The prompt dataset is comprised of multiple prompts, each of which gets processed by the LLM to produce a set of completions. The next step is to collect feedback from human labelers on the completions generated by the LLM.
In the human feedback portion of reinforcement learning with human feedback. First, you must decide what criterion you want the humans to assess the completions on. This could be any of the issues discussed so far like helpfulness or toxicity. Once you’ve decided, you will then ask the labelers to assess each completion in the data set based on that criterion.
At this stage, you have everything you need to train the Reward model. While it has taken a fair amount of human effort to get to this point, by the time you’re done training the reward model, you won’t need to include any more humans in the loop. Instead, the reward model will effectively take place off the human labeler and automatically choose the preferred completion during the oral HF process.
Fine Tuning with Reinforcement Learning
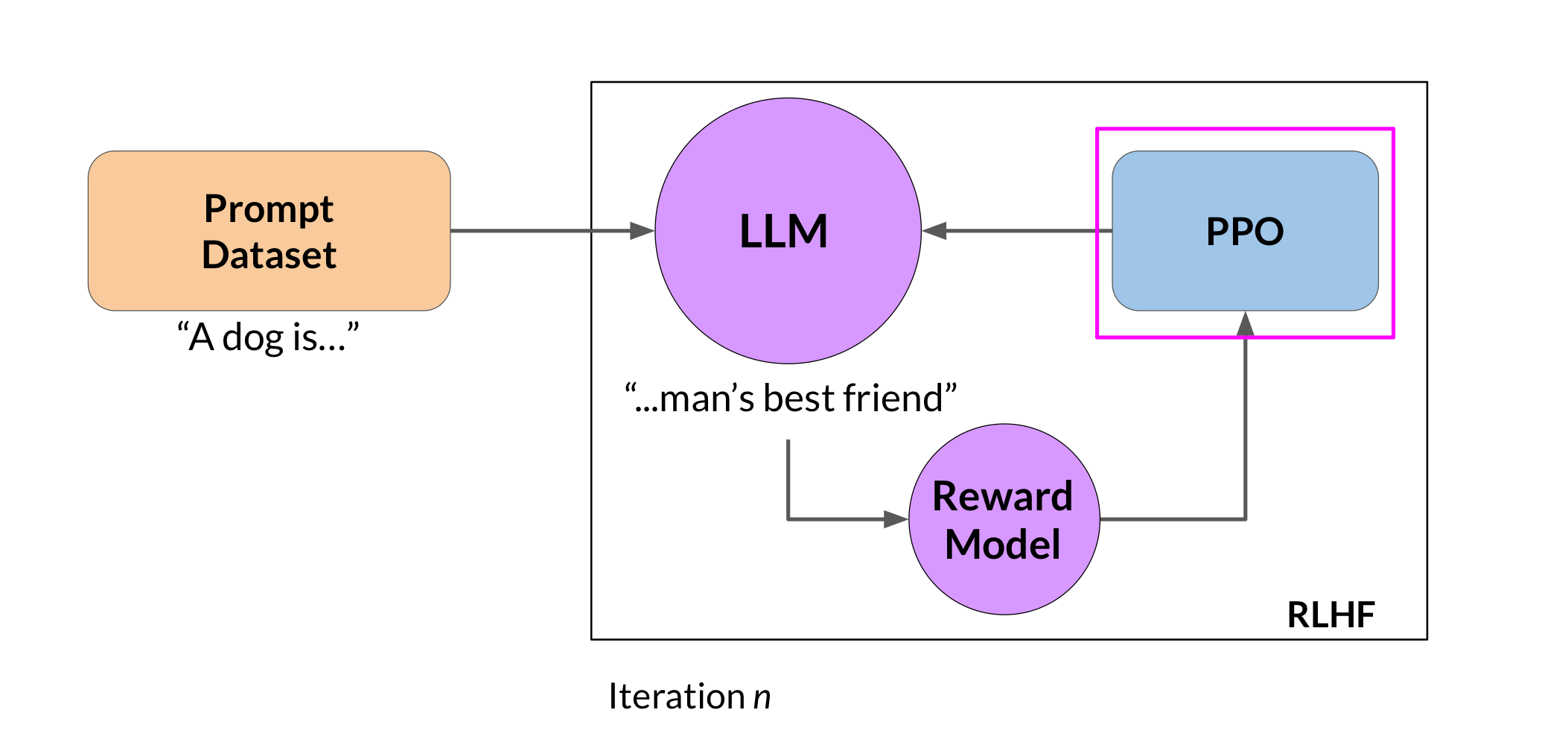
First, you’ll pass a prompt from your prompt dataset. In this case, a dog is, to the instruct LLM, which then generates a completion, in this case a furry animal. Next, you sent this completion, and the original prompt to the reward model as the prompt completion pair.
The reward model evaluates the pair based on the human feedback it was trained on, and returns a reward value. A higher value such represents a more aligned response. A less aligned response would receive a lower value.
You’ll then pass this reward value for the prompt completion pair to the reinforcement learning algorithm to update the weights of the LLM, and move it towards generating more aligned, higher reward responses. Let’s call this intermediate version of the model the RL updated LLM. These series of steps together forms a single iteration of the RLHF process. These iterations continue for a given number of epochs, similar to other types of fine tuning.
One detail we haven’t discussed yet is the exact nature of the reinforcement learning algorithm. This is the algorithm that takes the output of the reward model and uses it to update the LLM model weights so that the reward score increases over time. There are several different algorithms that you can use for this part of the RLHF process. A popular choice is proximal policy optimization or PPO for short.
Proximal Policy Optimization (PPO)
PPO stands for Proximal Policy Optimization, which is a powerful algorithm for solving reinforcement learning problems. As the name suggests, PPO optimizes a policy, in this case the LLM, to be more aligned with human preferences. Over many iterations, PPO makes updates to the LLM.
The updates are small and within a bounded region, resulting in an updated LLM that is close to the previous version, hence the name Proximal Policy Optimization. Keeping the changes within this small region result in a more stable learning. The goal is to update the policy so that the reward is maximized. PPO is popular because it has the right balance of complexity and performance.
Prepare Reward Model and Evaluate Toxicity
During PPO, only a few parameters will be updated. Specifically, the parameters of the ValueHead. The number of trainable parameters can be computed as (n + 1)*m, where n is the number of input units and m is the number of output units. The +1 term in the equation takes into account the bias term. A frozen copy of the PPO which will not be fine-tuned - a reference model. This reference model will represent the LLM before detoxification.
Prepare Reward Model
We ask human labelers to give feedback on the output’s toxicity. However, it can be expensive to use them for the entire fine-tuning process. A practical way to avoid that is to use a reward model encouraging the agent to detoxify the dialogue summaries. The intuitive approach would be to do some form of sentiment analysis across two classes (nothate and hate) and give a higher reward if there is higher a chance of getting class nothate as an output.
We will use Meta AI’s RoBERTa-based hate speech model for the reward model. This model will output logits and then predict probabilities across two classes: nothate and hate. The logits of the output nothate will be taken as a positive reward. Then, the model will be fine-tuned with PPO using those reward values. Hugging Face inference pipeline is used to simplify the code for the toxicity reward model. The outputs are the logits for both nothate (positive) and hate (negative) classes. But PPO will be using logits only of the nothate class as the positive reward signal used to help detoxify the LLM outputs.
Evaluate Toxicity
To evaluate the model before and after fine-tuning/detoxification you need to set up the toxicity evaluation metric. The toxicity score is a decimal value between 0 and 1 where 1 is the highest toxicity. The toxicity measurement aims to quantify the toxicity of the input texts using a pretrained hate speech classification model.
Perform Fine-Tuning to Detoxify the Summaries
Here we are going to optimize a Reinforcement Learning Policy against the reward model using Proximal Policy Optimization (PPO).
Set up the configuration parameters. Load the ppo_model and the tokenizer. You will also load a frozen version of the model ref_model. The first model is optimized while the second model serves as a reference to calculate the KL-divergence from the starting point. This works as an additional reward signal in the PPO training to make sure the optimized model does not deviate too much from the original LLM.
learning_rate=1.41e-5
max_ppo_epochs=1
mini_batch_size=4
batch_size=16
config = PPOConfig(
model_name=model_name,
learning_rate=learning_rate,
ppo_epochs=max_ppo_epochs,
mini_batch_size=mini_batch_size,
batch_size=batch_size
)
ppo_trainer = PPOTrainer(config=config,
model=ppo_model,
ref_model=ref_model,
tokenizer=tokenizer,
dataset=dataset["train"],
data_collator=collator)
Fine-Tune the Model
The fine-tuning loop consists of the following main steps:
- Get the query responses from the policy LLM (PEFT model).
- Get sentiments for query/responses from hate speech RoBERTa model.
- Optimize policy with PPO using the (query, response, reward) triplet.
output_min_length = 100
output_max_length = 400
output_length_sampler = LengthSampler(output_min_length, output_max_length)
generation_kwargs = {
"min_length": 5,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True
}
reward_kwargs = {
"top_k": None, # Return all scores.
"function_to_apply": "none", # You want the raw logits without softmax.
"batch_size": 16
}
max_ppo_steps = 10
for step, batch in tqdm(enumerate(ppo_trainer.dataloader)):
# Break when you reach max_steps.
if step >= max_ppo_steps:
break
prompt_tensors = batch["input_ids"]
# Get response from FLAN-T5/PEFT LLM.
summary_tensors = []
for prompt_tensor in prompt_tensors:
max_new_tokens = output_length_sampler()
generation_kwargs["max_new_tokens"] = max_new_tokens
summary = ppo_trainer.generate(prompt_tensor, **generation_kwargs)
summary_tensors.append(summary.squeeze()[-max_new_tokens:])
# This needs to be called "response".
batch["response"] = [tokenizer.decode(r.squeeze()) for r in summary_tensors]
# Compute reward outputs.
query_response_pairs = [q + r for q, r in zip(batch["query"], batch["response"])]
rewards = sentiment_pipe(query_response_pairs, **reward_kwargs)
# You use the `nothate` item because this is the score for the positive `nothate` class.
reward_tensors = [torch.tensor(reward[not_hate_index]["score"]) for reward in rewards]
# Run PPO step.
stats = ppo_trainer.step(prompt_tensors, summary_tensors, reward_tensors)
ppo_trainer.log_stats(stats, batch, reward_tensors)
print(f'objective/kl: {stats["objective/kl"]}')
print(f'ppo/returns/mean: {stats["ppo/returns/mean"]}')
print(f'ppo/policy/advantages_mean: {stats["ppo/policy/advantages_mean"]}')
print('-'.join('' for x in range(100)))
Evaluate the Model Quantitatively
Load the PPO/PEFT model back in from disk and use the test dataset split to evaluate the toxicity score of the RL-fine-tuned model. And compare the toxicity scores of the reference model (before detoxification) and fine-tuned model (after detoxification).
toxicity [mean, std] after detox: [0.05650319952771745, 0.07164365341668623]
Percentage improvement of toxicity score after detoxification:
mean: -74.17%
std: -86.57%