Chat Bot, Based on End to End Memory Networks
Question Answer model trained on Facebook Babi Dataset, Based on the paper End to End Memory Networks
Introduction
What is a Chat Bot?
A Chatbot is a computer program that facilitates technological and human communication through various input methods, such as text, voice and gesture. Chatbots serve the purpose of digital assistants, virtual assistants, AI assistants and much more. The recent technological advancement like Natural Language Processing(NLP), Artificial Intelligence(AI), Data Mining and Machine Learning(ML) have resulted in the creation of advanced AI Chatbots that are useful to businesses and individuals alike.
How are Chat Bots trained?
To train AI bots, it is paramount that a huge amount of training data is fed into the system to get sophisticated services. A hybrid approach is the best solution to enterprises looking for complex chatbots. The queries which cannot be answered by AI bots can be taken care of by linguistic chatbots. The data resulting from these basic bots can then be further applied to train AI bots, resulting in the hybrid bot system.
Data
The bAbI project was conducted by Facebook AI research team in 2015 to solve the problem of automatic text understanding and reasoning in an intelligent dialogue agent. To make the conversation with the interface as human as possible the team developed proxy tasks that evaluate reading comprehension via question answering. The tasks are designed to measure directly how well language models can exploit wider linguistic context. For our project, the subset of Babi Data Set from Facebook Research is used.
We will be developing a simple chatbot that can answer questions based on a “story” given to it. So without any further ado let’s get started!
Model Input and Response
So the type of data we’re gonna be working with has three main components story, question and answer. So for an example, we can have a simple story of
STORY: Jane went to the store, Mike ran to the bedroom;
And then we’ll have a yes or no question.
And the question here is: Is Mike in the store?
And our network is going to be able to understand that since Mike ran to the bedroom, he is not in the store.
So we have a correct ANSWER: NO.
Paper
So we are going be following along with a paper called End-to-End Memory Networks by the authors: Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus. Here is the link to the paper.
So the overall idea of the model is that it’s going to take in a discrete set of inputs X1, X2 …..all the way to Xn. And those will be the actual sentences or stories and will be stored in the memory.
And then we’ll also take a corresponding query/question Q and then we are going to output an answer A.
Each of the X, Q, and A are going to contain symbols coming from a dictionary with V amount of words. We will be calling V a vocabulary. So we will have a set or dictionary that contains the entire vocabulary across the entire data sets. And we will have a vocabulary length as well.
There are three main components to the End-to-End network.
- Input Memory Representation
- Output Memory Representation
- Generating Final Prediction
Let’s see what a single layer looks like:
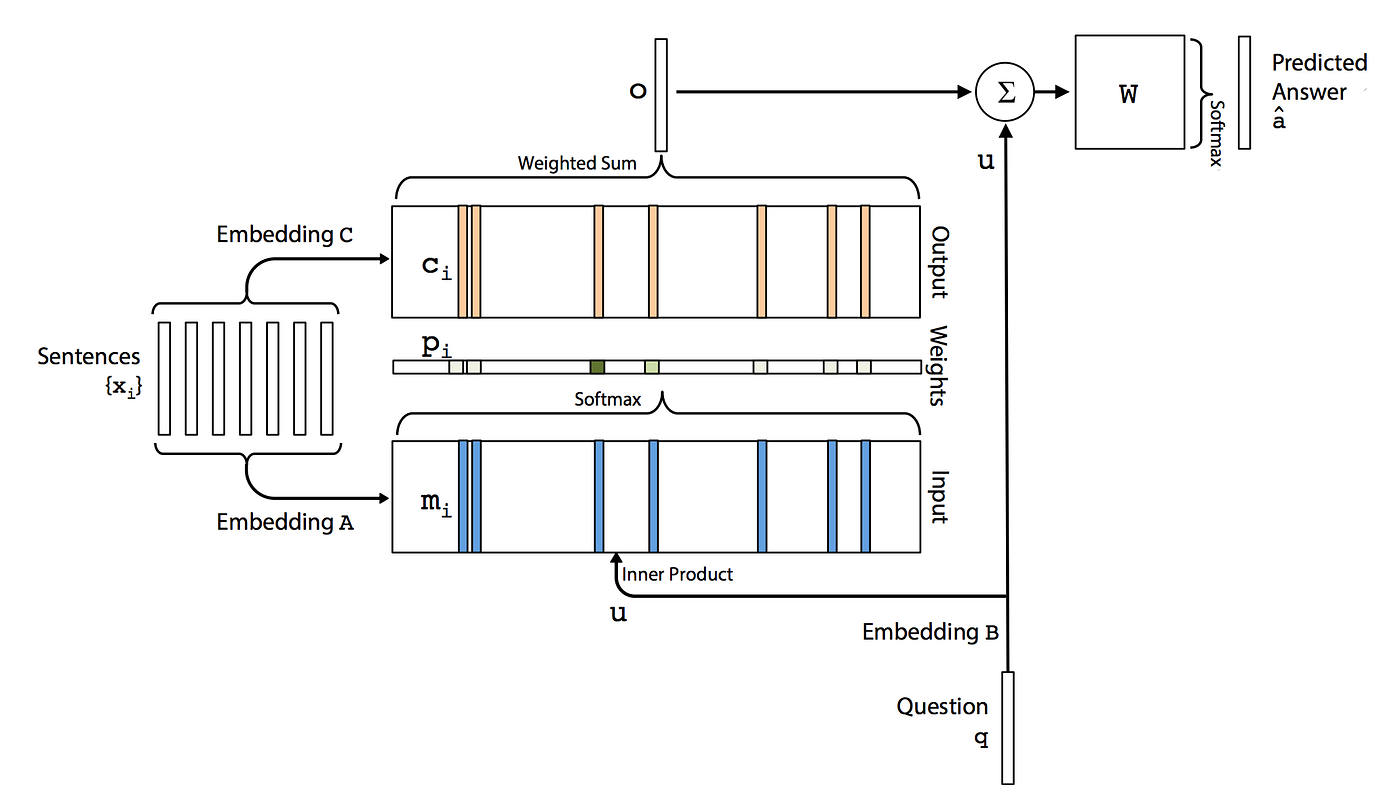
Input Memory Representation
What we are going to receive is an input set of X1, X2, X3……Xn. These are the sentences or stories to be stored in memory. We will have to convert that entire set of X’s into memory vectors. We will call M_i. We essentially have two types of encoders, and the bottom one is the M_i.
We will be using Keras for embedding these sentences. And then we later on have another embedding, an encoder process for C_i, and we will also be getting the question or query called as Q and that will also be embedded. We will embed that to obtain an internal state which we will label U. So at the bottom of the diagram we have question Q that is going through an embedding process and then we have the result which is the internal state of the embedding inside the single layer called U. Within this single layer, we are going to compute the match between U and memory M_i by taking the inner product followed by a Softmax operation.
Output Memory Representation
For the output memory representation, each X_i has a corresponding output vector C_i. Then the response vector from the memory O is then a sum over the transformed input C_i weighted by the probability vector from the input. And because the function from input to output is smooth, we can then compute gradients and back propagate through this.
Generating Final Prediction
Then the final third step is generating a single final prediction. So in this single layer case what we are gonna do is the sum of the output vector O and the input embedding U is passed through a final weight matrix W. And then a soft max that is essentially going to give us probabilities of the predicted answer which is used to produce the predicted label.
We can then expand this single layer into multiple layers. We are going to take the output of one of the single layers and have that be the input for the next layer. The logic is essentially the same as what we saw in the single layer. We are just repeating it over and over again.
Modeling
The modeling is carried out using Keras. Before we jump into modeling the data is loaded and the sentences are vectorised. The Neural network consists of Input Encoder M, Input Encoder C and Question Encoder.
Let’s do all the necessary imports:
from keras.models import Sequential, Model
from tensorflow.keras.layers import Embedding
from keras.layers import Input, Activation, Dense, Permute, Dropout, add, dot, concatenate, LSTM
Building the Network
# PLACEHOLDER
input_sequence = Input((max_story_len,))
question = Input((max_question_len,))
# INPUT ENCODER M
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_len, output_dim=64))
input_encoder_m.add(Dropout(0.3))
# INPUT ENCODER C
input_encoder_c = Sequential()
input_encoder_c.add(Embedding(input_dim=vocab_len, output_dim=max_question_len))
input_encoder_c.add(Dropout(0.3))
# QUESTION ENCODER
question_encoder = Sequential()
question_encoder.add(Embedding(input_dim=vocab_len, output_dim=64, input_length=max_question_len))
question_encoder.add(Dropout(0.3))
# ENCODED <----- ENCODER(INPUT)
input_encoded_m = input_encoder_m(input_sequence)
input_encoded_c = input_encoder_c(input_sequence)
question_encoded = question_encoder(question)
match = dot([input_encoded_m, question_encoded], axes=(2,2))
match = Activation('softmax')(match)
response = add([match, input_encoded_c])
response = Permute((2,1))(response)
answer = concatenate([response, question_encoded])
answer = LSTM(32)(answer)
answer = Dropout(0.5)(answer)
answer = Dense(vocab_len)(answer) # (samples, vocab_size) # YES/NO
answer = Activation('softmax')(answer)
model = Model([input_sequence, question], answer)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
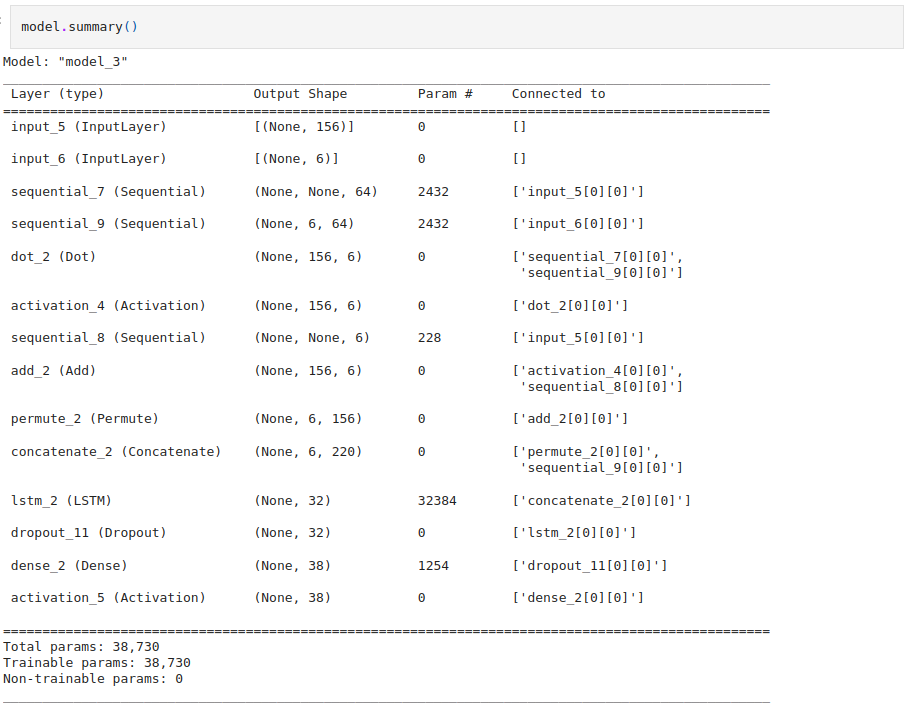
The model summary is as follows:
We will be training the model for 150 epocs here:
history = model.fit([input_train, question_train],answers_train, batch_size=32, epochs=150, validation_data=([input_test,question_test],answers_test))
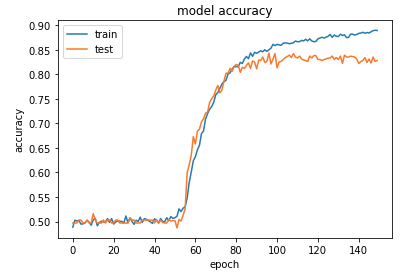
The model results on train and test data is as follows:
The model can be now tested against own stories and question:
st = "John left the kitchen . Sandra dropped the football in the garden ."
qs = "Is the football in the garden ?"
mydata = [(st.split(),qs.split(),'yes')]
#Vectorising
my_story,my_ques,my_ans = vectorize(mydata)
#Prediction
pred_results = model.predict(([ my_story, my_ques]))
#Generate prediction from model
val_max = np.argmax(pred_results[0])
for key, val in tokenizer.word_index.items():
if val == val_max:
k = key
print("Predicted answer is: ", k)
print("Probability of certainty was: ", pred_results[0][val_max])
The predicted answer and the probabilities are as follows:
